先前經朋友介紹看了這部影片認識了 Whisper,覺得對自己做字幕會很有幫助。但苦於個人電腦太過老舊,沒有辦法本機執行。剛好又認識到了 Google Colab 這個線上的執行環境,想寫一下如何合併兩者,在線上讓 Whisper AI 聽寫字幕或是逐字稿的方法。
Whisper
首先進入 Google Colab
選擇 檔案/新增筆記本

在空白筆記本上 +程式碼 加入要執行的命令
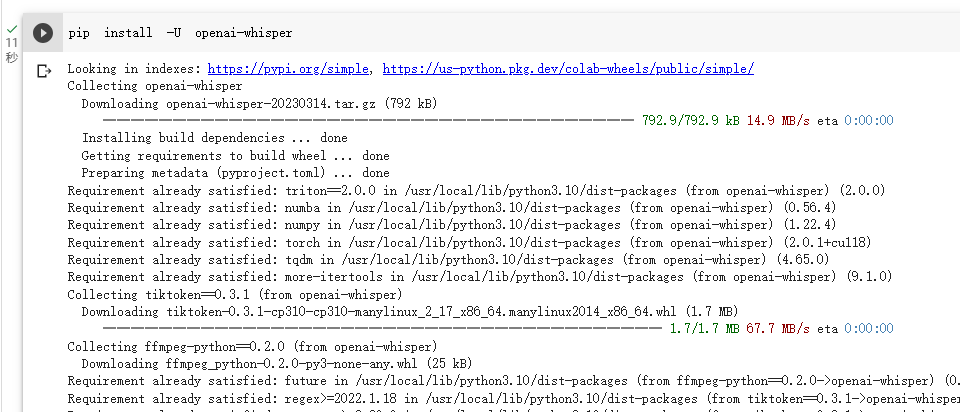
pip install -U openai-whisper
!whisper --language English --model large-v2 --device cuda <<檔案名稱>>
命令上就只有安裝 Whisper 跟使用 Commandline 執行而已,! 開頭在 Colab 代表執行 Shell 命令。因為官方的 Whisper 有 Commandline 介面,所以執行起來很方便。只是還有一些東西要設定:
點選右上角的連線:
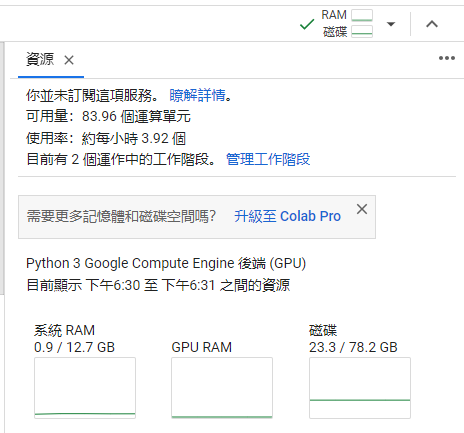
如果有看影片介紹或是實際測試過會知道有沒有用 GPU CUDA 速度會差非常多,所以我們加了 --device cuda 參數。但也同時要開啟 Colab 執行階段的 GPU。連線後點選顯示 RAM、磁碟的圖示:
![]()
會進入到資源分頁:
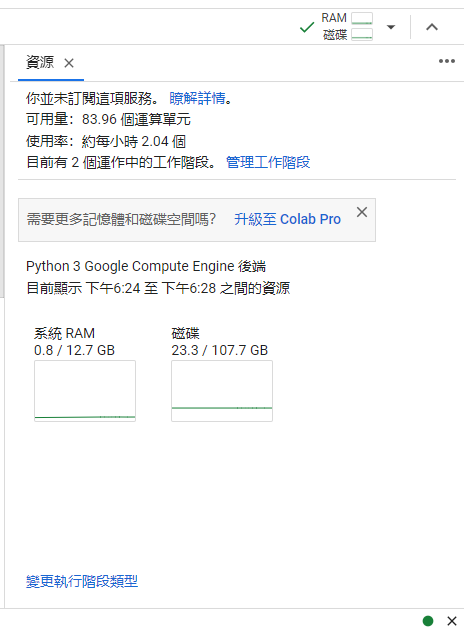
選擇 變更執行階段類型,開啟 GPU,應該只要用到 T4 即可:

如果沒有閒置 GPU 可以使用會需要付費,點選 瞭解詳情。Whisper 使用應該用 Pay As You Go 就好,我只有買 100 單位,依照經驗使用一小時大概耗費 2 ~ 4 單位上下,100 單位可以用很久。(注意運算單元有使用期限 90 天,一次不要買太大量)
設定後會要重新連線,選擇確定:

設定成功會看到資源分頁多了 GPU 資訊:
準備就緒後執行 PIP 安裝 Whisper:
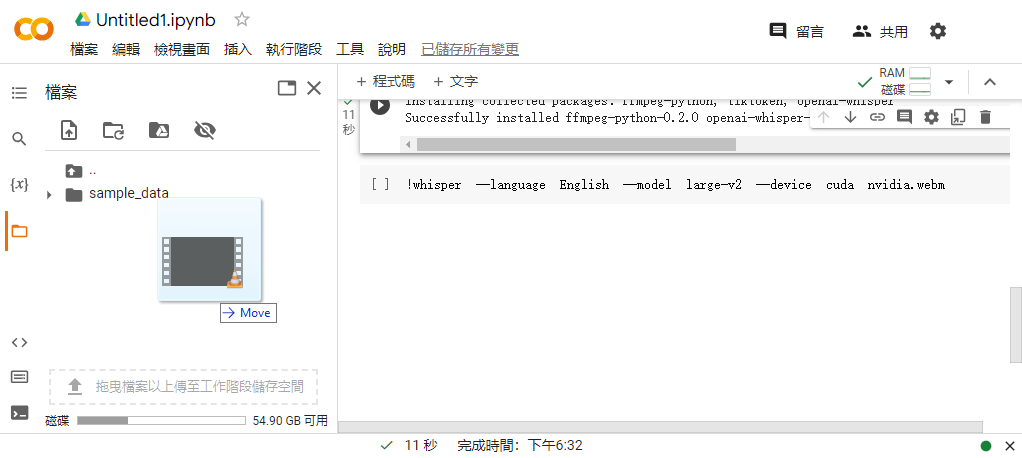
點選畫面左邊的資料夾圖示,拖曳上傳要製作字幕的聲音或是影片:
有的時候會覺得 Colab 的上傳很慢,其實也可以連結到 Google Drive。先上傳到 Google Drive 再搬到 Colab 根目錄,或是 Whisper 命令直接路徑輸入 Google Drive 路徑都可以。使用完畢後建議再按同一個按鈕撤銷 Google Drive 對這個 Colab 筆記的授權:
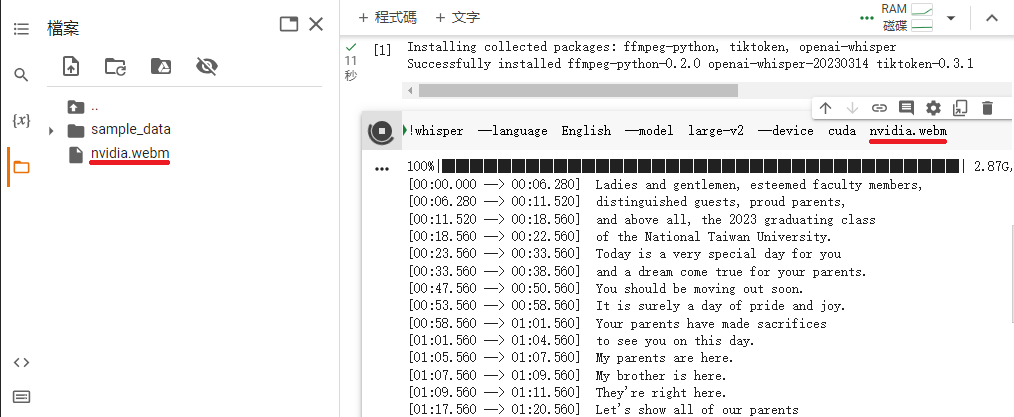
上傳完成後就可以輸入對應的檔名開始產生字幕了。參數方面 --language 是語言,支援的語言清單依照官方文件請參考 這裡。--model 是語言模型,理論上越大效果越好也越慢。模型的清單官方列在 這裡,上面沒有 large-v2 但實際上是抓得到的,我也習慣直接用 large-v2。
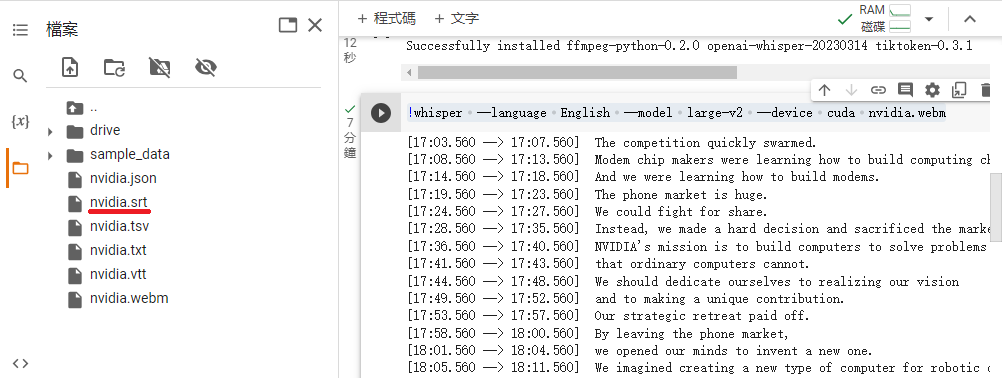
算完字幕檔、逐字稿會放在根目錄,就可以下載下來校對使用了:
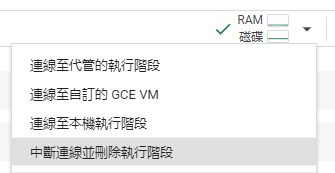
最後記得終止連線避免浪費購買的點數:
faster-whisper
Faster Whisper 是 Whisper 的重新實作,號稱有四倍以上的加速。在 Colab 上使用因為沒有 Commandline 介面需要 Python Code 輸出 .srt,但已經有人寫好了。要使用的話命令是:
pip install faster-whisper
from faster_whisper import WhisperModel
import math
def convert_seconds_to_hms(seconds):
hours, remainder = divmod(seconds, 3600)
minutes, seconds = divmod(remainder, 60)
milliseconds = math.floor((seconds % 1) * 1000)
output = f"{int(hours):02}:{int(minutes):02}:{int(seconds):02},{milliseconds:03}"
return output
model_path = "whisper-large-v2-ct2/"
# Run on GPU with FP16
model = WhisperModel(model_path, device="cuda", compute_type="float16")
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
#model = WhisperModel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("file.mp4", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
count = 0
with open('file.srt', 'w') as f: # Open file for writing
for segment in segments:
count +=1
duration = f"{convert_seconds_to_hms(segment.start)} --> {convert_seconds_to_hms(segment.end)}\n"
text = f"{segment.text.lstrip()}\n\n"
f.write(f"{count}\n{duration}{text}") # Write formatted string to the file
print(f"{duration}{text}",end='')
From: https://github.com/guillaumekln/faster-whisper/discussions/93#discussion-5021241
WhisperX
WhisperX 是號稱在 faster-whisper 上再加強字幕 timestamp 校正的版本。根據使用經驗好像英文的字幕時間軸有變好、但是中文反而變差。在猜測是聲音的 Alignment Model,如果不是 WAV2VEC2 或是 VOXPOPULI 效果可能就有限或是幫倒忙。
如果想在 Colab 使用,命令如下:
pip install git+https://github.com/m-bain/whisperx.git
pip install light-the-torch
!ltt install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 torchtext==0.14.1
!whisperx --language English --model large-v2 --device cuda <<檔案名稱>>
祝大家製作字幕順利。